Constituency methodology¶
Introduction¶
When policy changes in the UK - taxes, benefits, or public spending - it affects places and people differently. PolicyEngine UK builds tools to analyze incomes, jobs, and population patterns in each constituency. This documentation explains how we create a microsimulation model that works at the constituency level. The system combines workplace surveys of jobs and earnings, HMRC tax records, and population statistics. We map data between 2010 and 2024 constituency boundaries, estimate income distributions, and optimize geographic weights.
This guide shows how to use PolicyEngine UK for constituency analysis. We start with data collection, transform it for modeling, and build tools to examine policies. The guide provides examples and code to implement these methods. Users can measure changes in household budgets, track employment, and understand economic patterns on different constituencies. This document starts with data collection from workplace surveys, tax records, and population counts, then explains how we convert this data into usable forms through income brackets and boundary mapping. It concludes with technical details about accuracy measurement and calibration, plus example code for analysis and visualization.
Data¶
In this section, we describe three main data sources that form the foundation of our constituency-level analysis: earning and jobs data from NOMIS ASHE, income statistics from HMRC, and population age distributions from the House of Commons Library.
Earning and jobs data¶
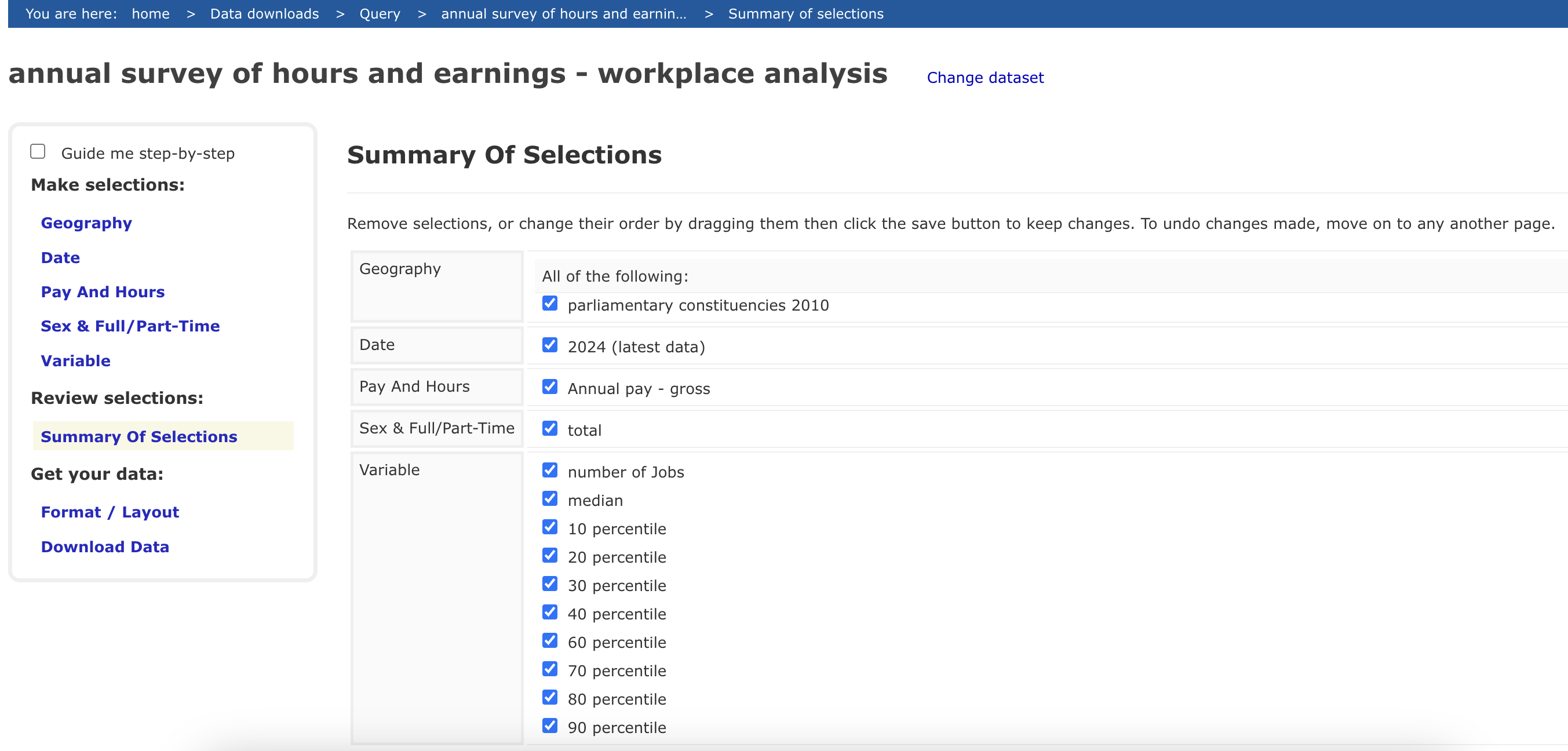
Data is extracted from NOMIS Annual Survey of Hours and Earnings (ASHE) - workplace analysis dataset, containing number of jobs and earnings percentiles for all UK parliamentary constituencies from the NOMIS website. This dataset is stored as nomis_earning_jobs_data.xlsx. To download the data, follow the variable selection process shown in the image below:
Income data¶
Income data for UK parliamentary constituencies is obtained from HMRC. This dataset provides detailed information about income and tax by Parliamentary constituency with confidence intervals, and is stored as total_income.csv, including two key variables:
total_income_count: the total number of taxpayers in each constituencytotal_income_amount: the total amount of income for all taxpayers in each constituency
We use these measures to identify similar constituencies when employment distribution data is missing. Our approach assumes that constituencies with similar income patterns (measured by both taxpayer counts and total income) will have similar earnings distributions. The following table shows the dataset:
| code | name | total_income_count | total_income_amount |
|---|---|---|---|
Loading ITables v2.3.0 from the init_notebook_mode cell...
(need help?) |
Population data by age¶
Population data by age groups for UK parliamentary constituencies can be downloaded from the House of Commons Library data dashboard. The dataset provides detailed age breakdowns for each UK constituency, containing population counts for every age from 0 to 90+ years old across all parliamentary constituencies in England, Wales, Northern Ireland, and Scotland. The data is stored as age.csv. The following table shows the dataset:
| code | name | all | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 | 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 | 88 | 89 | 90+ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Loading ITables v2.3.0 from the init_notebook_mode cell...
(need help?) |
Preprocessing¶
In this section, we detail two key preprocessing steps necessary for our constituency-level analysis: converting earnings percentiles into practical income brackets, and mapping between different constituency boundary definitions (2010 to 2024).
Convert earning percentiles to brackets¶
To analyze earnings data effectively, we convert earning percentiles into earning brackets through the following process:
First, we estimate the full distribution of earnings by:
Using known percentile data (10th to 90th) from the ASHE dataset
Extending this to estimate the 90th-99th percentiles using ratios derived from this government statistics report
This estimation allows us to map earnings data into brackets that align with policy thresholds.
The following code and visualization demonstrate this process using an example constituency:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Sample data for Darlington
income_data = {
'parliamentary constituency 2010': ['Darlington'],
'constituency_code': ['E14000658'],
'Number of jobs': ['31000'],
'10 percentile': [13298.0],
'20 percentile': [16723.0],
'30 percentile': [20778.0],
'40 percentile': [23407.0],
'50 percentile': [27158.0],
'60 percentile': [30471.0],
'70 percentile': [33812.0],
'80 percentile': [40717.0],
'90 percentile': [55762.0],
'91 percentile': [58878.0],
'92 percentile': [62394.4],
'93 percentile': [66722.3],
'94 percentile': [71952.0],
'95 percentile': [78804.5],
'96 percentile': [87640.7],
'97 percentile': [100083.5],
'98 percentile': [123526.5],
'100 percentile': [179429.0]
}
income_sample = pd.DataFrame(income_data)
# Excel Data Method
def load_real_data():
# Read Excel data
income_real = pd.read_excel("nomis_earning_jobs_data.xlsx", skiprows=7)
income_real.columns = income_real.iloc[0]
income_real = income_real.drop(index=0).reset_index(drop=True)
# Select and rename columns
columns_to_keep = [
'parliamentary constituency 2010',
'constituency_code',
'Number of jobs',
'Median',
'10 percentile',
'20 percentile',
'30 percentile',
'40 percentile',
'60 percentile',
'70 percentile',
'80 percentile',
'90 percentile'
]
income_real = income_real[columns_to_keep]
income_real = income_real.rename(columns={'Median': '50 percentile'})
return income_real
# Plotting function
def plot_constituency_distribution(income_df, constituency_name, detailed=True):
constituency_data = income_df[income_df['parliamentary constituency 2010'] == constituency_name].iloc[0]
percentiles = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 91, 92, 93, 94, 95, 96, 97, 98, 100]
income_values = [
0,
constituency_data['10 percentile'],
constituency_data['20 percentile'],
constituency_data['30 percentile'],
constituency_data['40 percentile'],
constituency_data['50 percentile'],
constituency_data['60 percentile'],
constituency_data['70 percentile'],
constituency_data['80 percentile'],
constituency_data['90 percentile'],
constituency_data['91 percentile'],
constituency_data['92 percentile'],
constituency_data['93 percentile'],
constituency_data['94 percentile'],
constituency_data['95 percentile'],
constituency_data['96 percentile'],
constituency_data['97 percentile'],
constituency_data['98 percentile'],
constituency_data['100 percentile']
]
valid_data = [(p, v) for p, v in zip(percentiles, income_values) if pd.notna(v)]
filtered_percentiles, filtered_income = zip(*valid_data)
plt.figure(figsize=(8, 6))
plt.plot(filtered_percentiles, filtered_income, marker='o')
plt.xlabel('Percentiles')
plt.ylabel('Income')
plt.title(f'Income Distribution for {constituency_name}')
plt.grid(True)
plt.show()
# Plot sample data (Darlington with detailed percentiles)
plot_constituency_distribution(income_sample, 'Darlington', detailed=True)
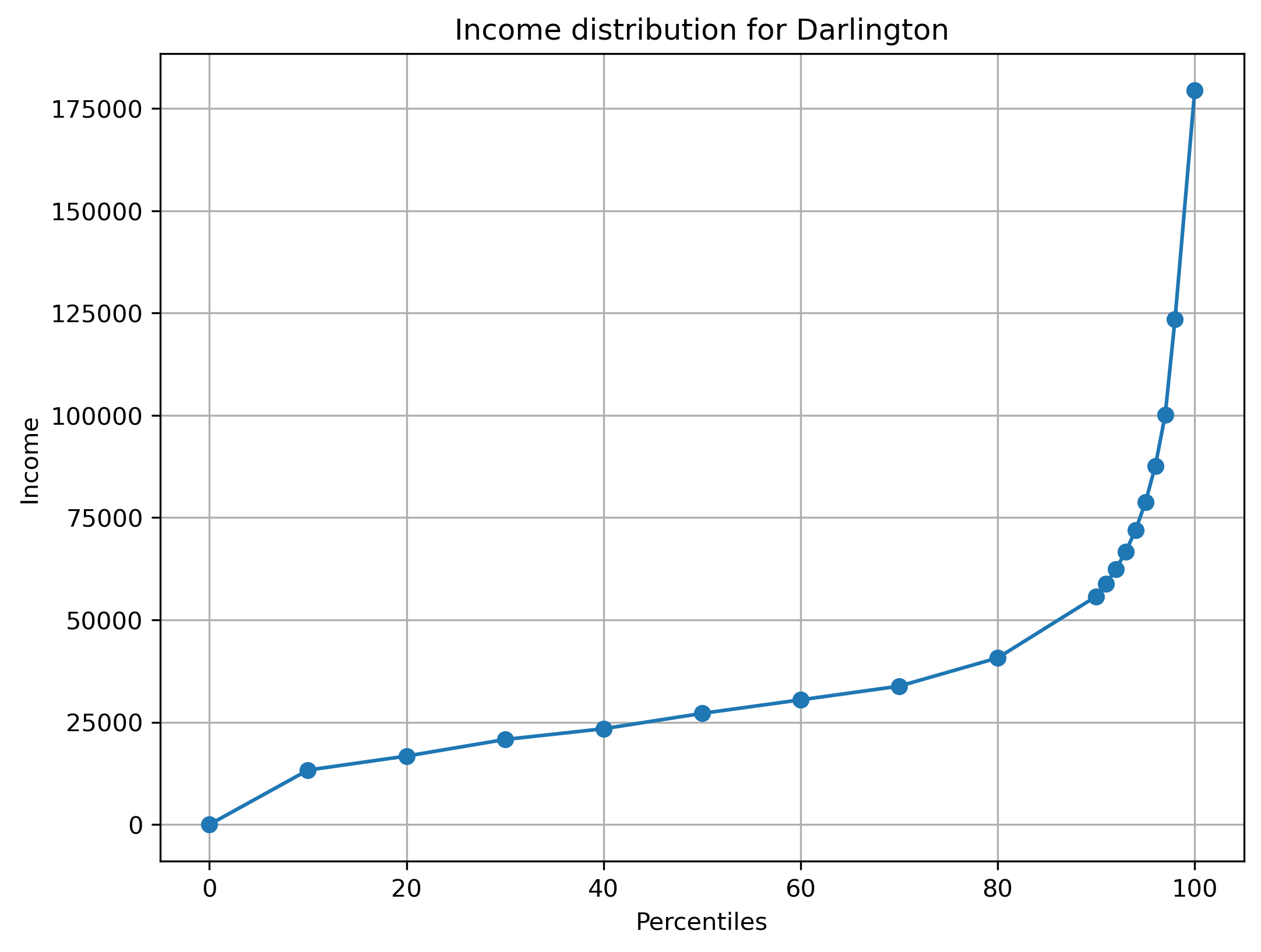
After estimating the full earnings distribution, we convert the data into income brackets. We calculate the number of jobs and total earnings for each constituency and income bracket based on the estimated earnings distribution. When we encounter constituencies with missing data, we estimate their earnings distribution pattern using data from constituencies with similar total number of taxpayers and total income levels.
The Python script create_employment_incomes.py generates employment_income.csv containing number of jobs (employment_income_count) and total earnings (employment_income_amount) for each constituency and income bracket. The following table shows employment and income across different brackets for constituencies:
| code | name | employment_income_lower_bound | employment_income_upper_bound | employment_income_count | employment_income_amount |
|---|---|---|---|---|---|
Loading ITables v2.3.0 from the init_notebook_mode cell...
(need help?) |
Mapping constituencies from 2010 to 2024¶
PolicyEngine uses HMRC income data which aligns with 2010 constituency boundaries; to handle this issue and align it with 2024 constituency boundaries definitions, we follow these processes:
Download the mapping data from the ONS website that contains the official lookup table between 2010 and 2024 Westminster Parliamentary Constituencies.
Create a mapping matrix (650 x 650) which maps each constituency from 2010 to corresponding constituency in 2024 using the
boundary_changes/mapping_matrix.pyscript. This is a many-to-many mapping, as 2010 constituencies can be split across multiple 2024 constituencies, and 2024 constituencies can contain parts of multiple 2010 constituencies. The matrix structure has rows representing 2010 constituencies and columns representing 2024 constituencies.For each row in the matrix (representing a 2010 constituency), normalize the weights so they sum to 1. This ensures that when we redistribute data from 2010 boundaries to 2024 boundaries, we maintain the correct proportions.
Methodology¶
This section describes our approach to creating accurate constituency-level estimates through three key components: a loss function for evaluating accuracy, a calibration process for optimizing weights, and the mathematical framework behind the optimization. To see how well this methodology performs in practice, you can check our detailed validation results page comparing our estimates against actual data at both constituency and national levels.
Loss function¶
The file loss.py defines a function create_constituency_target_matrix that creates target matrices for comparing simulated data against actual constituency-level data. The following process outlines how the function processes:
Takes three main input parameters: dataset (defaults to
enhanced_frs_2022_23), time_period (defaults to 2025), and an optional reform parameter for policy changes.Reads three files containing real data:
age.csv,total_income.csv, andemployment_income.csv.Creates a PolicyEngine Microsimulation object using the specified dataset and reform parameters.
Creates two main matrices:
matrixfor simulated values from PolicyEngine, andyfor actual target values from both HMRC (income data) and ONS (age data).Calculates total income metrics at the national level, computing both total amounts and counts of people with income.
Processes age distributions by creating 10-year age bands from 0 to 80, calculating how many people fall into each band.
Processes both counts and amounts for different income bands between £12,570 and £70,000, excluding people under 16 for employment income.
Maps individual-level results to household level throughout the
sim.map_result()function.The function returns both the simulated matrix and the target matrix
(matrix, y)which can be used for comparing the simulation results against actual data.
Calibration function¶
The file calibrate.py defines a main calibrate() function that performs weight calibration for constituency-level analysis.
It imports necessary functions and matrices from other files including
create_constituency_target_matrix,create_national_target_matrixfromloss.py, andtransform_2010_to_2024for constituency boundary transformations.Sets up initial matrices using the
create_constituency_target_matrixandcreate_national_target_matrixfunctions for both constituency and national level data.Creates a Microsimulation object using the
enhanced_frs_2022_23dataset.Initializes weights for 650 constituencies x 100180 households, starting with the log of household weights divided by constituency count.
Converts all the matrices and weights into PyTorch tensors to enable optimization.
Defines a loss function that calculates and combines both constituency-level and national-level mean squared errors into a single loss value.
Uses Adam optimizer with a learning rate of 0.1 to minimize the loss over 512 epochs.
Every 100 epochs during optimization, it updates the weights using the mapping matrix from 2010 to 2024 constituencies and saves the current weights to a
weights.h5file.Includes an
update_weights()function that applies the constituency mapping matrix to transform the weights between different boundary definitions.
Optimization mathematics¶
In this part, we explain the mathematics behind the calibration process that we discussed above. The optimization uses a two-part loss function that balances constituency-level and national-level accuracy, combining both local and national targets into a single optimization problem. The mathematical formulation can be expressed as follows:
For the constituency-level component, we have:
A set of households (\(j\)) with known characteristics (\(metrics_j\)) like income, age, etc.
A set of constituencies (\(i\)) with known target values (\(y_c\)) from official statistics
Weights in log space (\(w_{ij}\)) that we need to optimize for each household in each constituency
Using these components, we calculate predicted constituency-level statistics. For each constituency metric (e.g. total income), the predicted value is:
where \(\text{metrics}_j\) represents the household-level characteristics for that specific metric (e.g. household income). We use exponential of weights to ensure they stay positive.
To measure how well our predictions match the real constituency data, we calculate the constituency mean squared error:
where \(y_c\) are the actual target values from official statistics for each constituency. We use relative error (dividing by \(1 + y_c\)) to make errors comparable across different scales of metrics.
For the national component, we need to ensure our constituency-level adjustments don’t distort national-level statistics. We aggregate across all constituencies:
with corresponding mean squared error to measure deviation from national targets:
The total loss combines both constituency and national errors:
We initialize the weights using the original household weights from the survey data:
where 650 is the number of constituencies. These weights are then iteratively optimized using the Adam (Adaptive Moment Estimation) optimizer with a learning rate of 0.1. The optimization process runs for 512 epochs, with the weights being updated in each iteration:
This formulation ensures that the optimized weights maintain both local consistency at the constituency level and global accuracy for national-level statistics. The Adam optimizer adaptively adjusts the weights to minimize both constituency-level and national-level errors simultaneously, providing efficient convergence through adaptive learning rates and momentum. The resulting optimized weights allow us to accurately reweight household survey data to match both constituency-level and national statistics to obtain accurate estimates of income distributions, demographics, and policy impacts for each parliamentary constituency while maintaining consistency with national totals.